5分钟搞定 MySQL 到 ClickHouse 实时数据同步-CloudCanal 实战
-
简述
CloudCanal 近期实现了 MySQL(RDS) 到 ClickHouse 实时同步的能力,功能包含全量数据迁移、增量数据迁移、结构迁移能力,以及附带的监控、告警、HA等能力(平台自带)。
ClickHouse 本身并不直接支持 Update 和 Delete 能力,但是他自带的 MergeTree 系列表中 CollapsingMergeTree 和 VersionedCollapsingMergeTree 可变相实现实时增量的目的,并且性能完全够用,能够比较轻松达到 1k RPS 以上的能力。
接下来的文章,简要介绍 CloudCanal 是如何实现这个能力,以及作为用户我们怎么比较好的使用这个能力。
技术点
结构迁移
CloudCanal 默认提供结构迁移,默认选择 CollapsingMergeTree 作为表引擎,并增加一个默认字段
__cc_ck_sign,源主键作为 sortKey,如下示例:CREATE TABLE console.worker_stats ( `id` Int64, `gmt_create` DateTime, `worker_id` Int64, `cpu_stat` String, `mem_stat` String, `disk_stat` String, `__cc_ck_sign` Int8 DEFAULT 1 ) ENGINE = CollapsingMergeTree(__cc_ck_sign) ORDER BY id SETTINGS index_granularity = 8192ClickHouse 表引擎中,CollapsingMergeTree 和 VersionedCollapsingMergeTree 都能通过标记位按规则折叠数据,从而达到更新和删除的效果。VersionedCollapsingMergeTree 相比 CollapsingMergeTree 优势在于同一条数据的不同变更可以乱序写入,但是 CloudCanal 选择 CollapsingMergeTree 主要原因在于2点
-
- CloudCanal 中同一条记录必定是按源库变更顺序写入,不存在乱序情况
-
- 不需要维护 VersionedCollapsingMergeTree 中的 Version 字段(版本,也可以起其他名字)
所以 CloudCanal 选择了 CollapsingMergeTree 作为默认表引擎。
写数据
CloudCanal 写数据主要包含全量和增量两种,即单次搬迁存量数据和长期同步,两者写入略有不同。全量写入对端主要工作是批量和多线程,因为 CloudCanal 结构迁移默认设置了标记位字段
__cc_ck_signdefault 值为 1, 所以就不需要做特殊处理。对于增量, CloudCanal 则需要做 3 件事情。
- 转换 Update、Delete 操作为 Insert
这一步有两件事情要做,第一件是按照操作类型,填充标记字段值,其中 Insert 和 Update 为 1 ,Delete 为 -1 ,第二件是将对应增量数据的前镜像或者后镜像填充到结果记录中,以便后续 insert 写入。
for (CanalRowChange rowChange : rowChanges) { switch (rowChange.getEventType()) { case INSERT: { for (CanalRowData rowData : rowChange.getRowDatasList()) { rowData.getAfterColumnsList().add(nonDeleteCol); records.add(rowData.getAfterColumnsList()); } break; } case UPDATE: { for (CanalRowData rowData : rowChange.getRowDatasList()) { rowData.getBeforeColumnsList().add(deleteCol); records.add(rowData.getBeforeColumnsList()); rowData.getAfterColumnsList().add(nonDeleteCol); records.add(rowData.getAfterColumnsList()); } break; } case DELETE: { for (CanalRowData rowData : rowChange.getRowDatasList()) { rowData.getBeforeColumnsList().add(deleteCol); records.add(rowData.getBeforeColumnsList()); } break; } default: throw new CanalException("not supported event type,eventType:" + rowChange.getEventType()); } }- 按表归组
因为 IUD 操作已全部转换为 Insert, 且为全镜像(所有字段都填充了值),所以可以按表归组,然后批量写入。即使单线程也能满足大部分场景的同步性能要求。
protected Map<TableUnit, List<CanalRowChange>> groupByTable(IncrementMessage message) { Map<TableUnit, List<CanalRowChange>> data = new HashMap<>(); for (ParsedEntry entry : message.getEntries()) { if (entry.getEntryType() == CanalEntryType.ROWDATA) { CanalRowChange rowChange = entry.getRowChange(); if (!rowChange.isDdl()) { List<CanalRowChange> changes = data.computeIfAbsent(new TableUnit(entry.getHeader().getSchemaName(), entry.getHeader().getTableName()), k -> new ArrayList<>()); changes.add(rowChange); } } } return data; }- 并行写入
将按表归组的数据使用并行执行框架执行,具体不详述。
举个"栗子"
- 添加数据源
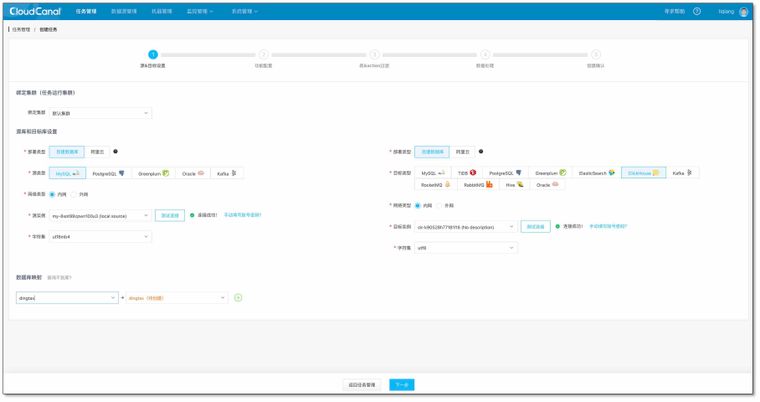
- 创建任务,选择数据源和库,并连接成功,点击下一步
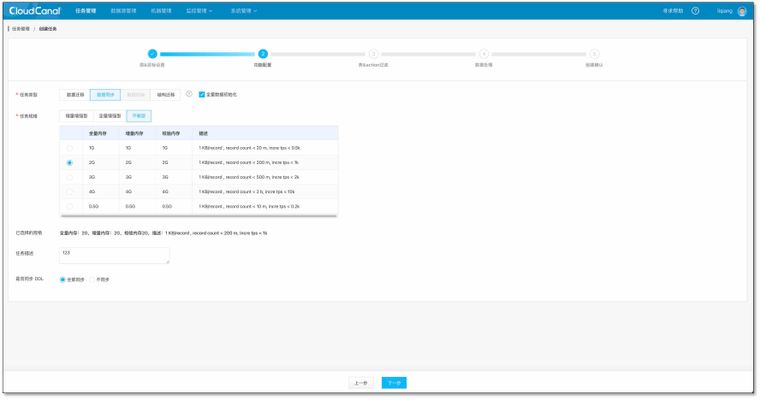
- 选择数据同步,建议规格至少选择 1 GB.目前 MySQL->ClickHouse 结构迁移自动过滤,所以选择无效。点击下一步
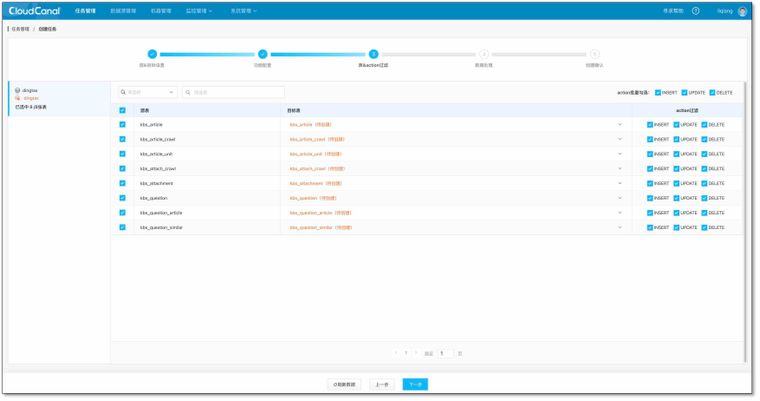
- 选择表,默认 ClickHouse 上创建
CollapsingMergeTree表引擎,并自动添加__cc_ck_sign折叠标记字段。点击下一步
- 选择字段,点击下一步
- 创建任务
- 等待任务自动结构迁移、全量迁移、数据同步追上
- 造点 Insert、Update、Delete 负载

- 延迟追平状态,停止负载
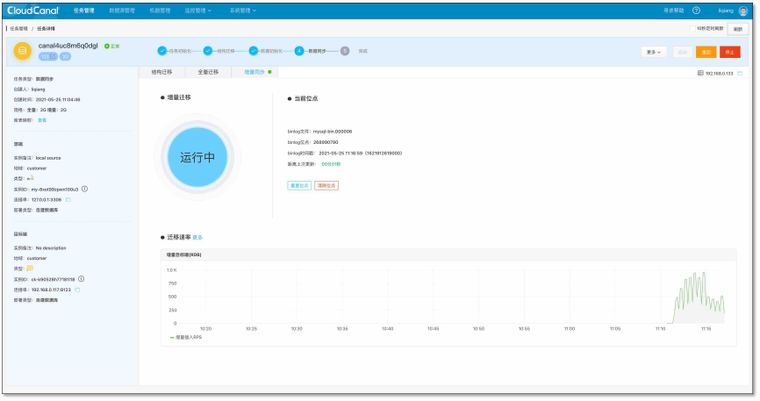
- 检查源端 MySQL 表数据,以其中一张表为例
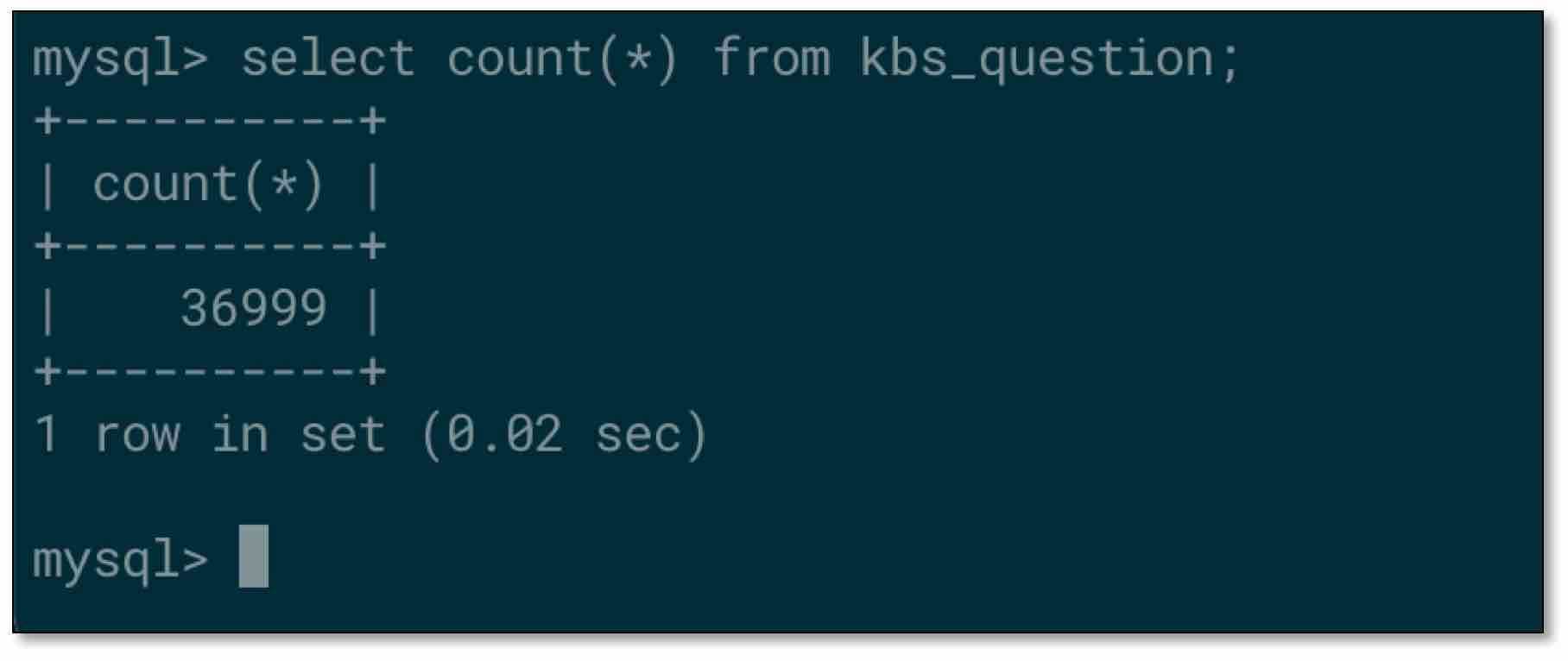
- 检查对端 ClickHouse 表数据,不一致?!!
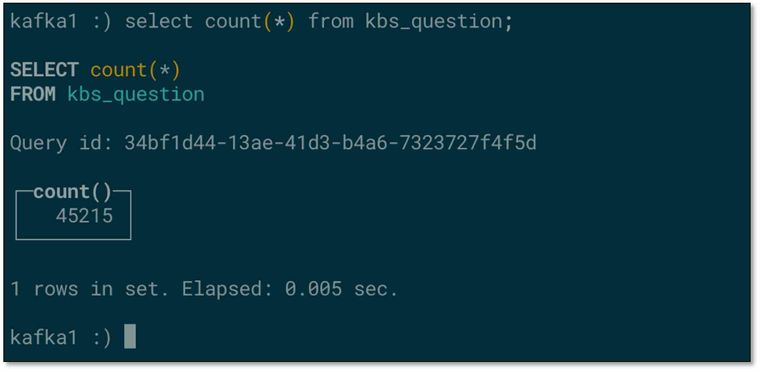
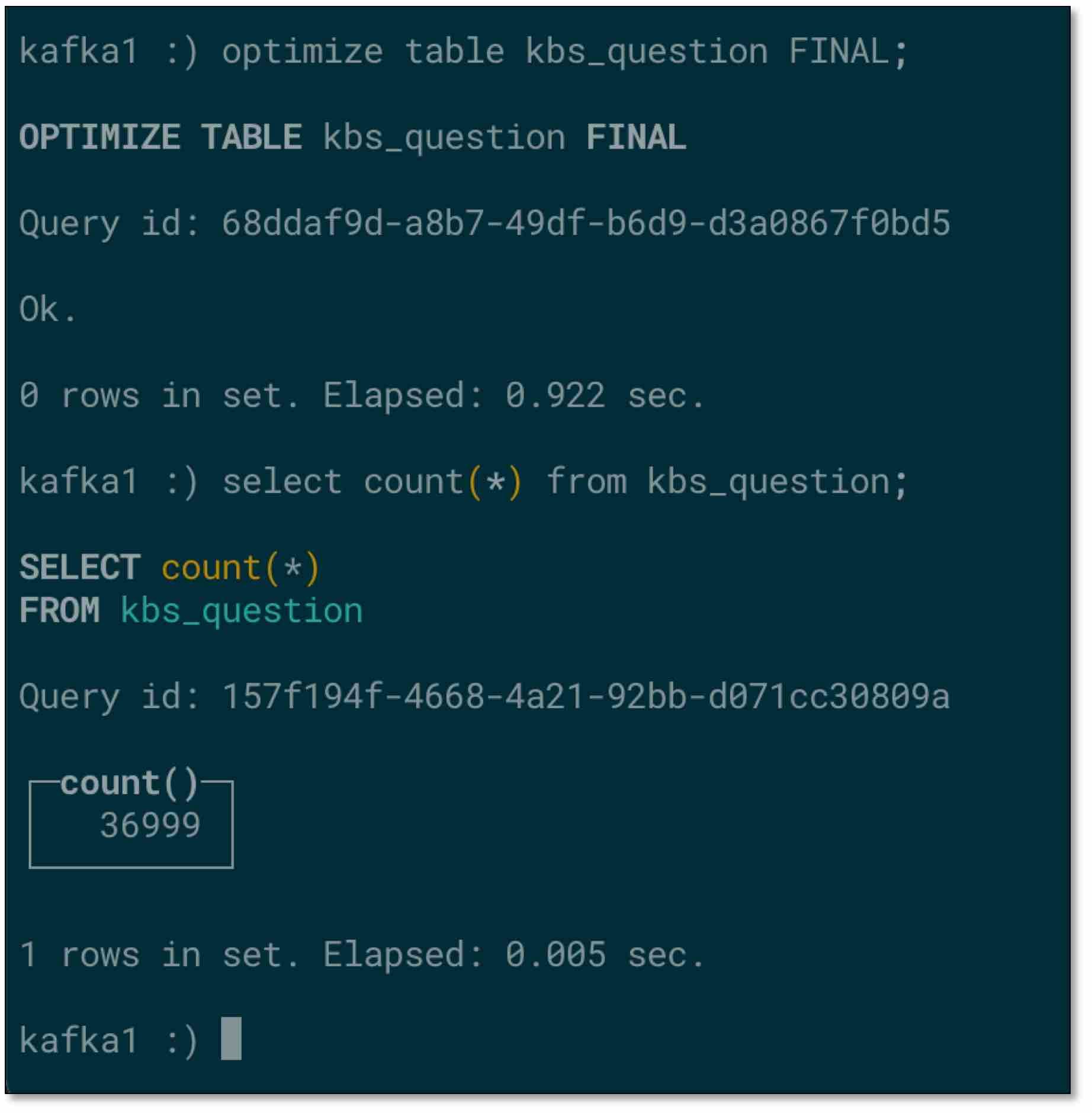
- 手动优化下表,数据一致。虽然可以等待 ClickHouse 自动优化,但是如果需要直接得到准确结果,可手动优化(注意:手动优化可能导致数据库机器压力过大)
常见问题
我在ClickHouse上已经创建了表怎么办?
目前比较建议直接使用 CloudCanal 自动结构迁移的方式来创建任务。
如果已建表为 CollapsingMergeTree 表引擎,请将标记位字段改成
__cc_ck_signInt8 DEFAULT 1`,再创建任务(此时就不再自动结构迁移,而是使用已存在表)。如果为其他表引擎,暂时不支持(主要是不支持增量能力,需要 CloudCanal 进一步探索)。
同步过去的数据什么时候合并?
当 CloudCanal 同步数据到 ClickHouse 时,ClickHouse 并不会实时合并数据,也没有一致性可言,所以一般情况是等待合并,或者直接手动合并(造成机器高负载、高IO),如
optimize table worker_stats FINAL。DDL 怎么做?
目前 CloudCanal 还未支持到 ClickHouse 的 DDL 同步,产品实现上,目前是忽略的。所以如果做 DDL ,加字段建议对端先加,再加源端,减字段反之。
总结
本文简要介绍了 CloudCanal 实现 MySQL(RDS) 到 ClickHouse 数据迁移同步的能力,具备一站式、数据实时特点,从技术点、例子、以及常见问题角度展开。文章如有错误,烦请大家勘误,后续也欢迎大家试用,提供宝贵的意见和建议。
文末,附上CloudCanal 社区版下载 ,欢迎大家使用
-